KIMI K2: OPEN AGENTIC INTELLIGENCEKIMI K2: OPEN AGENTIC INTELLIGENCE TECHNICAL REPORT OF KIMI K2 Kimi Team ABSTRACT
KIMI K2: OPEN AGENTIC INTELLIGENCE
TECHNICAL REPORT OF KIMI K2
Kimi Team
ABSTRACT
본 문서에서는 32 billion 활성화된 parameters와 1 trillion total parameters를 갖춘 Mixture-of-Experts(MoE) large language model인 Kimi K2를 소개한다. Muon에 novel QK-clip 기법을 결합해 training 불안정성을 해결하면서 Muon의 advanced token efficiency를 그대로 유지하는 MuonClip optimizer를 제안한다. MuonClip을 기반으로 K2는 15.5 trillion tokens로 사전학습(pre-training)되었으며, loss spike 없이 안정적으로 학습되었다. 사후 학습(post-training) 단계에서는 대규모 agentic data synthesis pipeline과 real/synthetic 환경에서의 상호작용을 통한 joint reinforcement learning(RL) 단계를 거쳐 모델의 역량을 획기적으로 개선한다.
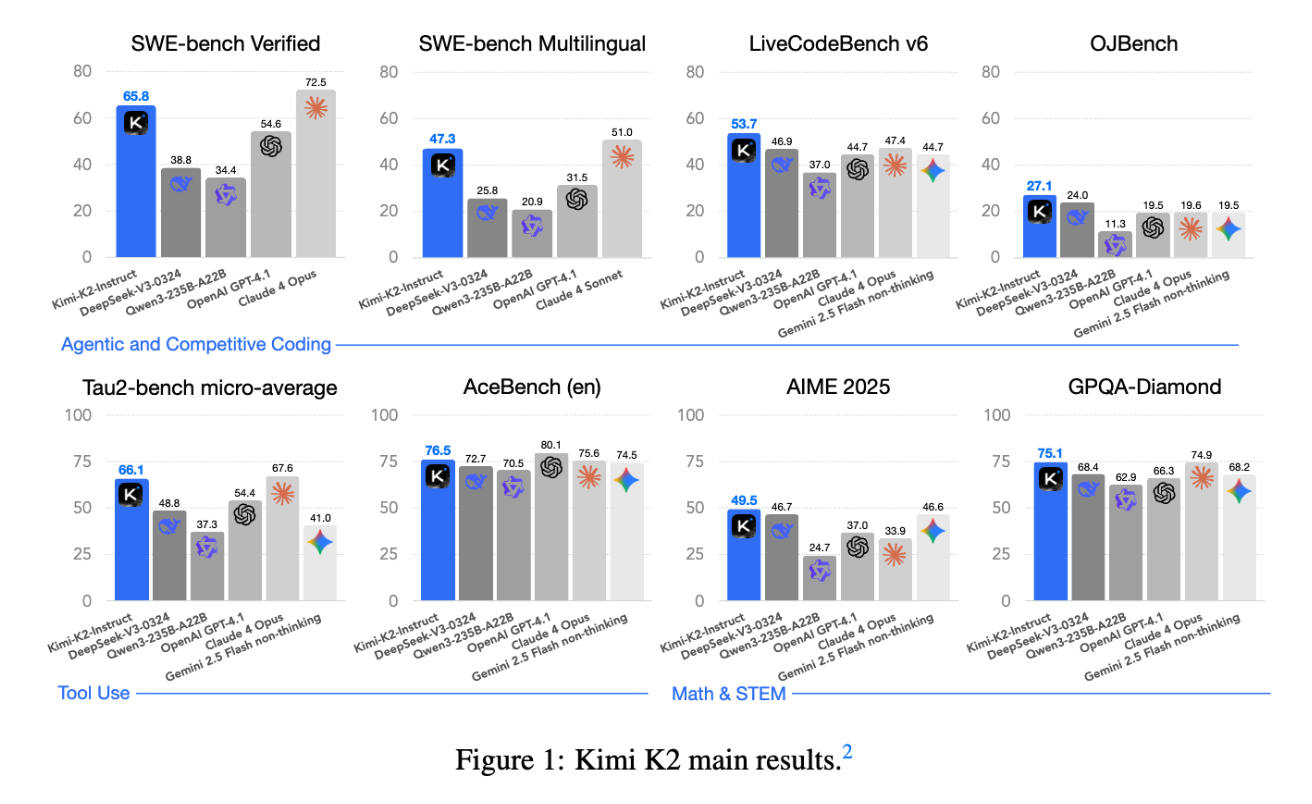
Kimi K2는 agentic capabilities에 강점이 있는 open-source non-thinking models 중에서 state-of-the-art performance를 달성한다. 구체적으로,
1.Tau2-Bench: 66.1
2.ACEBench (En): 76.5
3.SWE-Bench Verified: 65.8
4.SWE-Bench Multilingual: 47.3
등의 점수가 기존의 open/closed-sourced baselines를 능가한다. 또한 coding, mathematics, reasoning task에서도 뛰어난 성능을 보인다. 예를 들어, LiveCodeBench v6에서 53.7, AIME 2025에서 49.5, GPQA-Diamond에서 75.1, OJBench에서 27.1을 기록했다. 이러한 결과는 Kimi K2가 특히 software engineering 및 agentic tasks 분야에서 가장 강력한 open-source LLM 중 하나임을 입증한다. 모델의 base 및 post-trained checkpoints는 향후 agentic intelligence 연구와 응용을 촉진하기 위해 공개된다.
Mixture-of-Experts (MoE)란 무엇인가?
Mixture-of-Experts (MoE)는 대규모 언어 모델 아키텍처 설계 기법 중 하나로, “모델 전체”를 매번 사용하지 않고, 입력에 따라 일부 전문가(Expert)만 활성화시켜 처리하는 방식입니다. 이로 인해 계산량(FLOPs)과 메모리 사용량을 크게 줄이면서도, 모델의 전체 파라미터 수를 늘려 표현력을 확보할 수 있습니다.
1. 전통적인 트랜스포머와 MoE의 차이
구분
표준 트랜스포머
MoE 트랜스포머
파라미터 수
모든 계층(layer)의 모든 가중치를 매번 사용
전체 전문가 집합(수백 개 텐서)의 가중치 보유
활성화되는 파라미터
모델 전체
입력별로 소수의 전문가만 선택하여 활성화
연산 비용
입력 길이·모델 크기에 비례
동일 연산량(FLOPs) 대비 더 큰 모델 크기 사용 가능
장점
구조 단순, 구현 용이
대규모 파라미터로 성능 높이면서 효율성 유지
2. MoE 동작 원리
1.전문가(Expert) 풀(pool) 구성
예를 들어, Kimi K2에서는 384개의 전문가를 두고, 그중 입력마다 8개만 활성화(스파시티 48)합니다.2.라우터(Router) 네트워크
입력 토큰(또는 토큰 시퀀스)의 특성에 따라 가장 적합한 전문가 8개를 선택합니다.3.전문가별 처리
선택된 전문가 각각이 동일한 입력을 받아 독립적으로 처리한 뒤, 결과를 가중합하여 최종 출력을 만듭니다.4.전체 모델 파라미터
활성되지 않는 나머지 전문가는 해당 토큰 처리 시 계산에 참여하지 않아 연산 낭비가 없습니다.3. Kimi K2에서의 MoE 적용
총 전문가 수: 384개
활성화 전문가 수: 토큰당 8개 (스파시티 48)
모델 크기: 총 1.04조 파라미터, 활성 파라미터 326억
효과:
동일한 연산량(FLOPs)으로 파라미터 54% 증가 → 표현력 대폭 향상
활성 파라미터 감소(–13%) → 추론 효율성 개선MoE 설계 덕분에 Kimi K2는 “큰 모델을 효율적으로” 운용하면서도 코딩·추론·도구 사용 등 다양한 벤치마크에서 최상위급 성능을 달성할 수 있었습니다.
Muon 옵티마이저란 무엇인가?
Muon은 대규모 언어 모델을 더 적은 토큰으로 빠르고 효과적으로 학습하기 위해 고안된 최적화 알고리즘입니다. 전통적인 옵티마이저(예: AdamW)가 모델 파라미터를 업데이트할 때 학습 신호가 충분히 반영되지 않는 문제를 완화하기 위해, Muon은 다음 두 가지 핵심 아이디어를 도입합니다.
1.모멘텀 기반 일관된 RMS 스케일링
Muon은 매 스텝마다 과거 그래디언트의 지수이동평균(momentum)을 계산하고, 이를 뉴턴–슐츠(Newton–Schultz) 방법으로 정규화하여 RMS(제곱평균제곱근) 스케일을 일관되게 맞춥니다.
이를 통해 그래디언트 크기의 급격한 변동 없이 매 스텝 안정적인 학습률을 유지할 수 있습니다.
2.파라미터 업데이트 효율 극대화
Muon은 “msign” 연산을 사용해 그래디언트의 부호(sign) 정보와 RMS 스케일만으로 파라미터를 조정합니다.
이 방식은 불필요한 정보(그래디언트 크기 변화의 노이즈)를 제거하고, 핵심 방향성(+=, –=)에 집중함으로써 동일한 계산량 하에서 더 많은 학습 신호를 모델에 전달합니다.
결과적으로 Muon은토큰 효율(token efficiency): 단위 토큰당 더 많은 학습 신호 반영
안정성(stability): 그래디언트 폭주나 loss 스파이크 감소
를 동시에 달성하며, 대규모 언어 모델 훈련 시 AdamW 대비 더 빠른 수렴과 더 낮은 검증 손실을 보여 줍니다.
1 Introduction
대규모 언어 모델(LLMs)의 발전은 이제 Agentic Intelligence—모델이 복잡하고 동적인 환경에서 자율적으로 인식, 계획, 추론, 행동할 수 있는 능력—로의 패러다임 전환을 맞이하고 있다. 이는 정적 모방 학습을 넘어 모델이 상호작용을 통해 학습하고, 훈련 분포를 넘어 새로운 기술을 획득하며, 경험을 통해 행동을 조정하는 역량을 의미한다. Agentic intelligence는 static human-generated data의 한계를 극복하고, 탐험과 활용을 통해 초인적인 역량을 획득할 수 있다는 점에서 차세대 foundation models의 핵심 요소로 부상하고 있다. 이 역량은 tool use, software development, real-world autonomy 등 다양한 분야에 혁신적 영향을 미친다.
그러나 agentic intelligence 구현을 위해서는 pre-training과 post-training 모두에서 과제가 존재한다. Pre-training 단계에서는 제한된 고품질 데이터 하에서 token efficiency(토큰당 학습 신호)를 극대화해야 하며, post-training 단계에서는 사전 학습된 지식을 actionable behaviors로 전환해야 한다. 특히 multi-step reasoning, long-term planning, tool use 같은 agentic 역량은 자연 데이터에 드물게 나타나고 확장 비용이 높다. 이를 해결하기 위해서는 구조화된 고품질 agentic trajectories를 대규모로 합성하고, reinforcement learning(RL) 기법에 preferences와 self-critique를 도입해야 한다.
본 연구에서는 이러한 핵심 과제를 해결하고 agentic capability 한계를 돌파하기 위해 설계된 1.04 trillion-parameter Mixture-of-Experts(MoE) LLM Kimi K2를 제안한다. 주요 기여는 다음과 같다.
1.MuonClip Optimizer: token-efficient Muon 알고리즘에 stability-enhancing QK-Clip을 통합하여 15.5 trillion tokens 사전 학습 시 단 한 번의 loss spike 없이 안정적 학습을 달성.
2.Agentic Data Synthesis Pipeline: simulated/real 환경에서 다양한 tool-use demonstrations를 생성하여 high-fidelity, verifiable agentic interactions를 대규모로 구축.
2.RLVR + Self-Critique Framework: verifiable rewards(RLVR)와 self-critique rubric reward를 결합한 general reinforcement learning 전략을 설계하여 외부 과제 보상과 자체 평가를 병합.
Kimi K2는 non-thinking evaluation 환경에서도 Tau2-bench 66.1, ACEBench 76.5, SWE-bench Verified 65.8, SWE-bench Multilingual 47.3을 달성해 대부분의 open/closed-source 모델을 능가하며, GPT-4.1과 Claude 4 Opus의 격차를 좁혔다. 또한 LiveCodeBench v6, OJBench, AIME 2025, GPQA-Diamond 등 coding, mathematics, STEM benchmark에서도 최상위 성능을 보인다. LMSYS Arena leaderboard(2025-07-17)에서 1위 open-source 모델, 전체 5위를 기록함으로써 실사용자 평가에서도 우수성을 입증했다.
Agentic Intelligence 연구를 촉진하기 위해 Kimi K2의 base 및 post-trained checkpoints를 공개하며, 이를 통해 커뮤니티가 agentic intelligence를 탐구·개선·배포할 수 있도록 지원한다.
2 사전 학습(Pre-training)
Kimi K2의 베이스 모델은 1조 개 파라미터를 가진 혼합 전문가(MoE) 트랜스포머 모델로, 15.5조 개의 고품질 토큰으로 사전 학습되었습니다. 고품질 인간 생성 데이터의 가용성이 점차 제한됨에 따라, 토큰 효율(token efficiency)이 대규모 언어 모델 확장의 핵심 계수가 되고 있다고 가정합니다. 이를 해결하기 위해, 토큰 효율을 극대화하도록 명시적으로 설계된 사전 학습 기법 모음을 도입합니다. 구체적으로, 토큰 효율이 뛰어난 Muon 옵티마이저를 사용하고, QK-Clip 기법을 도입하여 학습 불안정성을 완화합니다. 또한, 합성 데이터 생성을 활용해 사용 가능한 고품질 토큰에서 더 많은 지능을 이끌어냅니다. 모델 아키텍처는 경험적 스케일링 법칙 분석에 기반해 DeepSeek-V3와 유사한 다중 헤드 잠재 어텐션(MLA)을 적용한 초고희소 MoE를 따릅니다. 기반 인프라는 학습 효율과 연구 효율을 모두 최적화하도록 구축되었습니다.
2.1 MuonClip: 가중치 클리핑을 통한 안정적 학습
Kimi K2는 토큰 효율이 뛰어난 Muon 옵티마이저에 가중치 감쇠(weight decay)와 일관된 RMS 스케일링을 결합하여 학습합니다. 이전 연구 Moonlight의 실험 결과, 동일한 컴퓨팅 예산과 모델 크기(따라서 동일한 학습 데이터 양) 하에서 Muon은 AdamW에 비해 토큰 효율이 크게 향상됨을 보여주어, 대규모 언어 모델 학습에서 토큰 효율 개선을 위한 효과적인 선택임을 확인했습니다.
Muon 확장 시 발생하는 학습 불안정성
효율적임에도 Muon을 대규모로 확장해 학습하면, 어텐션 로짓(attention logits) 폭주로 인한 학습 불안정성이 AdamW보다 더 자주 발생하는 문제가 드러났습니다. 기존의 완화 전략은 충분치 않았습니다. 예를 들어, logit soft-cap은 softmax에 들어가기 전 로짓 자체를 직접 클리핑하지만, 쿼리·키 내적(dot product)이 여전히 과도하게 커지기 전에만 동작합니다. 한편, Query-Key Normalization(QK-Norm)은 멀티헤드 잠재 어텐션(MLA)에서는 키 행렬이 추론 시 완전히 구성되지 않아 적용할 수 없습니다.
QK-Clip으로 Muon 안정화
이 문제를 해결하기 위해, 우리는 어텐션 로짓을 명시적으로 제어하는 새로운 가중치 클리핑 기법 QK-Clip을 제안합니다. QK-Clip은 업데이트 후 쿼리·키 프로젝션 가중치(Wq, Wk)를 재스케일링하여 로짓의 급격한 성장을 억제합니다.
입력 표현을 X라 할 때, 각 헤드 h의 쿼리·키·값 프로젝션은
Qh = X Whq, Kh = X Whk, Vh = X Whv
(Wq, Wk, Wv는 모델 파라미터)
어텐션 출력은
Oh = softmax( Qh Khᵀ/√d ) Vh
배치 B에서 softmax 입력값의 최대치(로짓 최대값)를 헤드별로 정의하면
Sₕₘₐₓ = (1/√d) maxₓ∈B max_{i,j} (Qhᵢ·Khⱼ)
QK-Clip은 Sₕₘₐₓ이 기준값 τ를 넘으면 Wq, Wk를 γ = min(1, τ/Sₘₐₓ) 비율로 축소합니다. 이때 순전파·역전파 연산은 변경되지 않고, 단지 로짓 과성장을 제어할 강도를 결정하는 신호로만 사용합니다.
단순 구현: 모든 헤드를 동일하게 클리핑
Wq ← γα Wq, Wk ← γ^(1–α) Wk
(Sₘₐₓ = max_h Sₕₘₐₓ, α=0.5 권장)
실제 관찰: 일부 헤드만 폭주하므로, 헤드별 스케일 γₕ = min(1, τ/Sₕₘₐₓ)을 적용
MLA(다중 헤드 잠재 어텐션)의 경우:
qC·kC (헤드 고유 성분) → √γₕ 스케일
qR (헤드 고유 로터리) → γₕ 스케일
kR (공유 로터리) → 변경 없음
MuonClip: 통합 옵티마이저
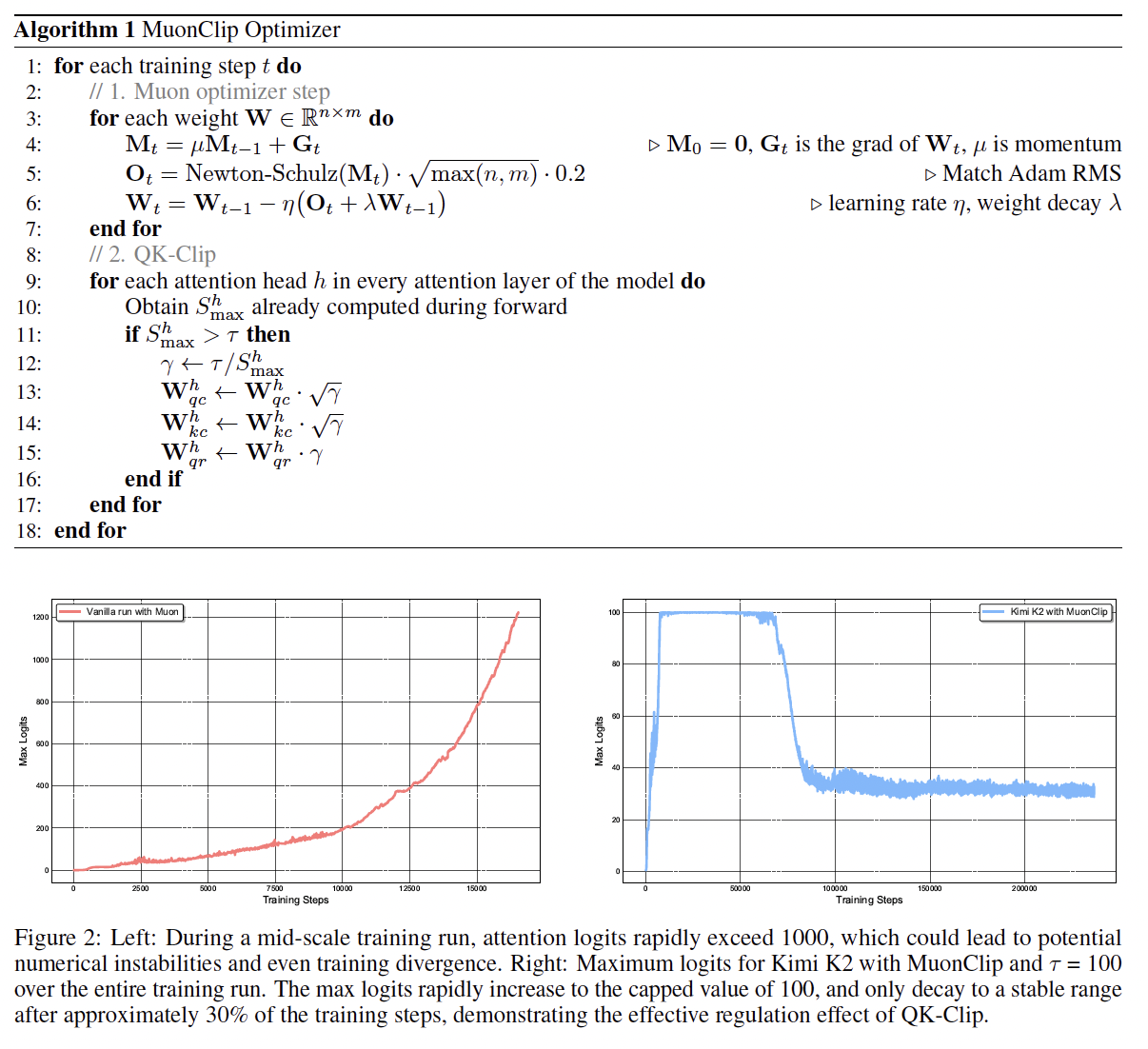
Muon 업데이트, 가중치 감쇠, 일관된 RMS 매칭, 그리고 QK-Clip을 하나로 합친 옵티마이저를 MuonClip이라 부릅니다(알고리즘 1 참고).
실험 1: 활성화 파라미터 9B, 전체 53B 규모 MoE 모델을 vanilla Muon으로 학습 시, 최대 어텐션 로짓이 1000 이상으로 폭증하여 학습 불안정(손실 급등·발산) 현상이 관측됨(그림 2 좌).
실험 2: MuonClip을 동일 설정에 적용해도 성능 저하 없이 Muon의 최적화 특성을 유지함을 확인.
실험 3: Kimi K2(대규모 MoE, τ=100) 학습 시, 초기 로짓이 100으로 캡핑되고 학습 진행에 따라 안정적 범위로 회복. 학습 손실 곡선은 단 한 번의 스파이크 없이 매끄럽게 유지됨(그림 2 우 및 그림 3).
이로써 MuonClip은 대규모 언어 모델 학습에서 어텐션 동역학을 견고하고 확장 가능하게 제어함을 검증했습니다.
 2.2 사전 학습 데이터: 재서술을 통한 토큰 효용(token utility) 향상
2.2 사전 학습 데이터: 재서술을 통한 토큰 효용(token utility) 향상
사전 학습(pre-training)에서의 토큰 효율(token efficiency)이란, 학습에 소모된 각 토큰이 모델 성능 개선에 기여하는 정도를 의미합니다. 토큰 효용(token utility)—각 토큰이 학습 신호로 전달하는 유효 정보량—을 높이면, 토큰당 모델 업데이트에 미치는 영향이 커져 토큰 효율이 직접적으로 개선됩니다. 이는 고품질 토큰의 공급이 제한적이고 최대한 활용해야 할 때 특히 중요합니다. 토큰 효용을 높이는 단순한 방법으로는 동일 토큰을 반복 학습하는 것이 있지만, 이는 과적합(overfitting)과 일반화(generalization) 저하를 초래할 수 있습니다.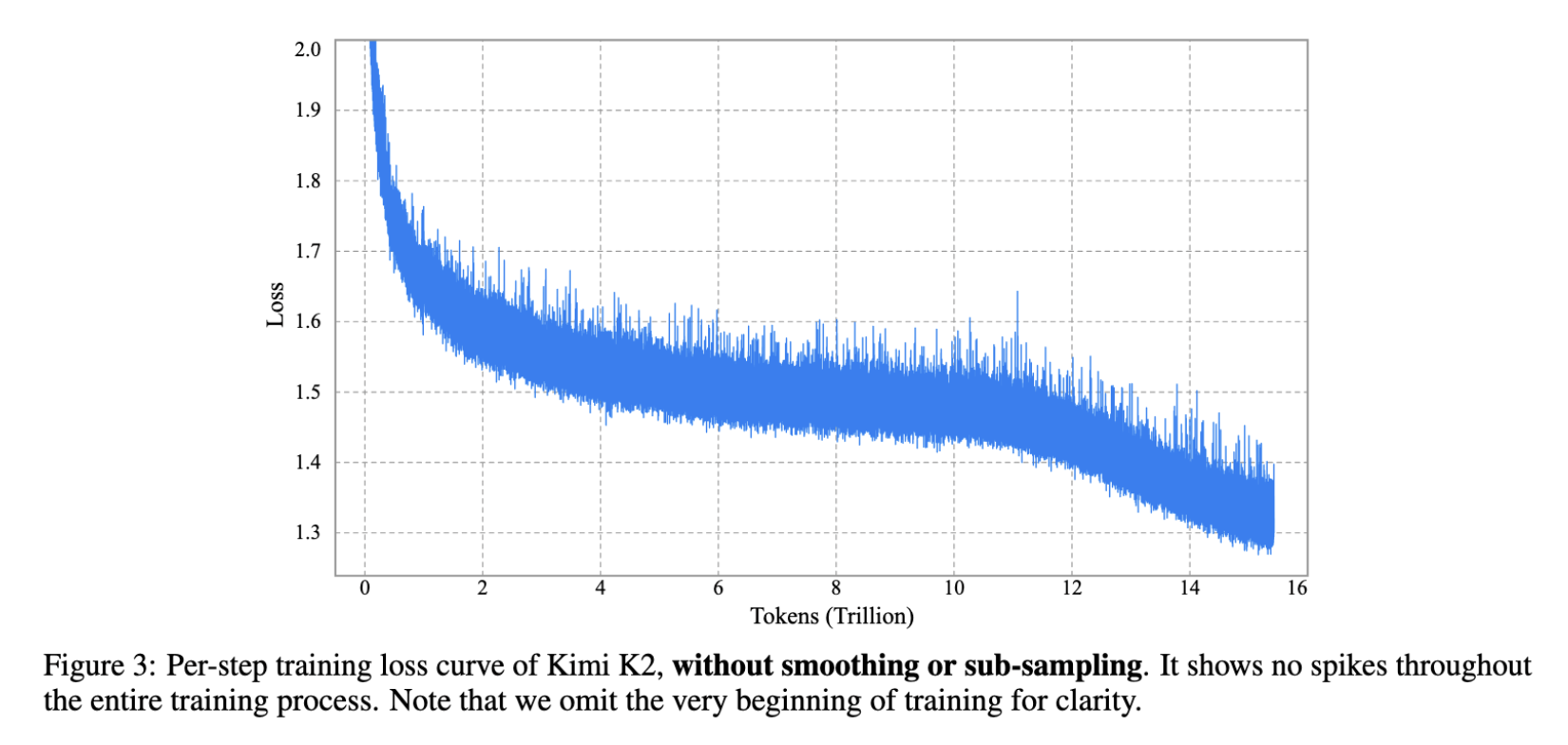 Kimi K2의 사전 학습 데이터에서 Kimi K1.5 대비 핵심 진전은, 토큰 효용을 증대시키기 위해 합성(synthetic) 데이터 생성 전략을 도입한 점입니다. 구체적으로, 고품질 토큰의 볼륨을 과도한 과적합 없이 증폭하기 위해 정교하게 설계된 재서술(rephrasing) 파이프라인을 활용합니다. 이 보고서에서는 지식(Knowledge) 도메인과 수학(Mathematics) 도메인에 각각 특화된 두 가지 재서술 기법을 설명합니다.
Kimi K2의 사전 학습 데이터에서 Kimi K1.5 대비 핵심 진전은, 토큰 효용을 증대시키기 위해 합성(synthetic) 데이터 생성 전략을 도입한 점입니다. 구체적으로, 고품질 토큰의 볼륨을 과도한 과적합 없이 증폭하기 위해 정교하게 설계된 재서술(rephrasing) 파이프라인을 활용합니다. 이 보고서에서는 지식(Knowledge) 도메인과 수학(Mathematics) 도메인에 각각 특화된 두 가지 재서술 기법을 설명합니다.
Knowledge Data Rephrasing
자연어 기반 지식 집약 텍스트를 사전 학습에 활용할 때, 단일 에포크(epoch)만으로는 충분한 지식 흡수가 어렵고, 다중 에포크 반복은 수익 체감(diminishing returns)과 과적합 위험 증가를 초래합니다. 고품질 지식 토큰의 토큰 효용을 향상하기 위해, 다음과 같은 합성 재서술 프레임워크를 제안합니다.
스타일 및 관점 다양성 프롬프트(Style- and perspective-diverse prompting): 언어적 다양성을 높이되 사실 정확성을 유지하도록, 여려 스타일과 관점으로 원문을 충실히 재서술하도록 유도하는 정교한 프롬프트를 적용합니다.
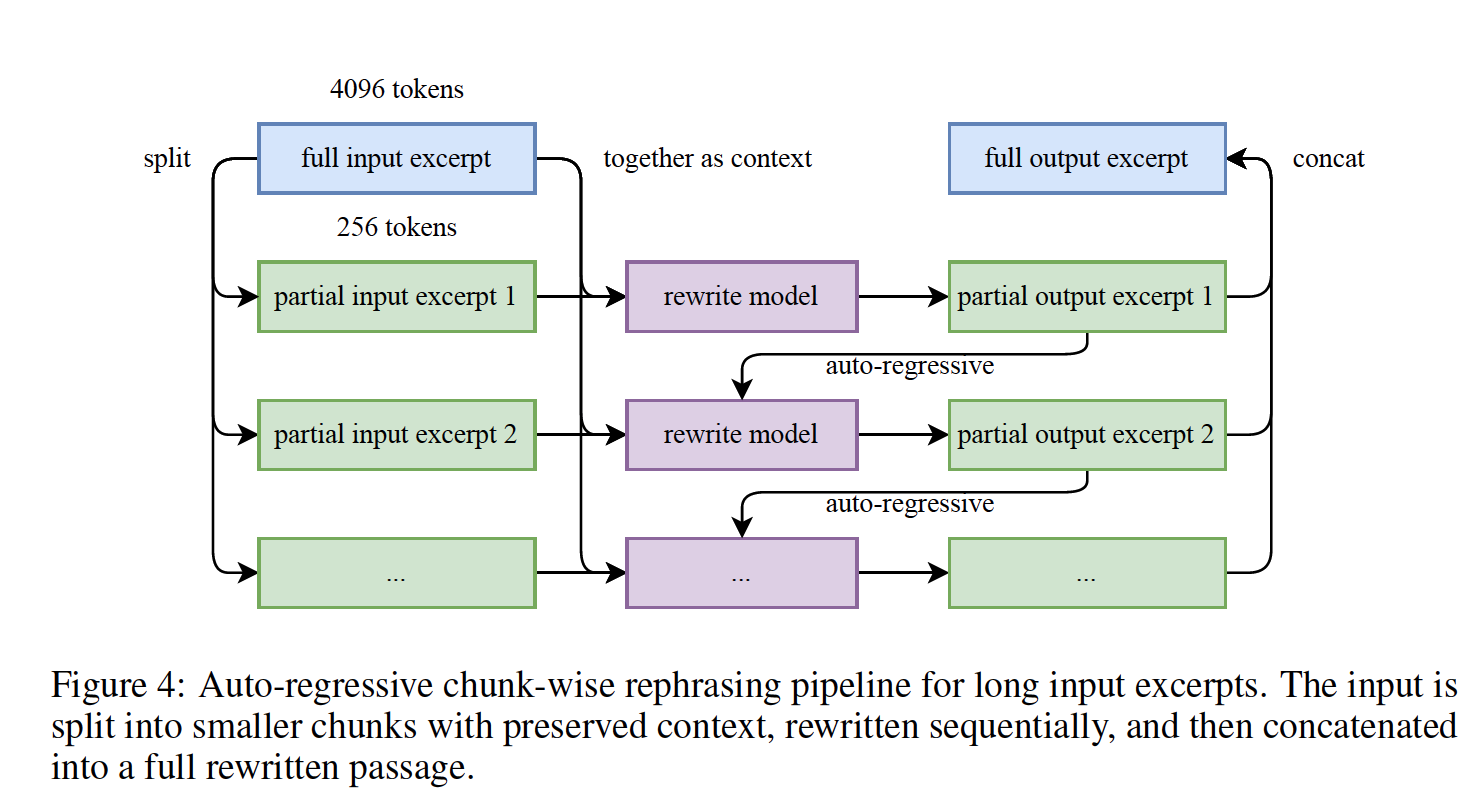
청크 단위 자동회귀 생성(Chunk-wise autoregressive generation): 장문도 전체 일관성을 보존하고 정보 손실을 방지하기 위해, 텍스트를 적절한 분량의 청크(chunk)로 나누어 개별적으로 재서술한 뒤 이어 붙이는 방식을 사용합니다. 이 기법은 LLM에서 종종 발생하는 출력 길이 제약을 완화합니다. 파이프라인 개요는 그림 4에 제시되어 있습니다.
충실도 검증(Fidelity verification): 재서술된 각 구간(segment)이 원문과 의미적으로 일치하는지 확인하는 충실도 검증을 수행하여, 학습 전 초기 품질 관리를 보장합니다.
재서술과 다중 에포크 반복(multi-epoch repetition)을 비교하기 위해, SimpleQA 데이터셋에서 세 가지 학습 전략을 시험했습니다.
1.원본 데이터셋을 10 에포크 반복 학습
2.데이터를 한 번 재서술한 뒤 10 에포크 반복 학습
3.데이터를 10회 재서술한 뒤 단일 에포크 학습
표 1에 보인 바와 같이, 재서술 횟수가 증가할수록 SimpleQA 정확도가 지속적으로 향상되어, 재서술 기반 증강의 효용을 입증했습니다. 이 방식을 대규모 지식 코퍼스에도 확장 적용했으며, 각 코퍼스는 최대 두 번까지 재서술했습니다.

 Mathematics Data Rephrasing
Mathematics Data Rephrasing
수학적 추론 능력을 강화하기 위해, 고품질 수학 문서를 SwallowMath 방식의 “학습 노트(learning-note)” 스타일로 재작성했습니다. 또한, 다른 언어로 된 고품질 수학 자료를 영어로 번역하여 데이터 다양성을 추가로 확대했습니다. 초기 실험에서 재서술된 데이터셋 하위집합이 유망한 결과를 보였지만, 합성 데이터 사용 전략을 지속 확장하는 것은 사실 정확성 유지, 환각(hallucination) 최소화, 대규모 확장성 확보 등 해결해야 할 과제로 남아 있습니다.
Pre-training Data Overall
Kimi K2의 사전 학습 코퍼스는 총 15.5조 개 토큰 분량의 엄선된 고품질 데이터로 구성되며, Web Text, Code, Mathematics, Knowledge 네 개 주 도메인을 아우릅니다. 대부분의 데이터 처리 파이프라인은 Kimi K1.5의 방법론을 따르며, 도메인별로 엄격한 정확성 및 품질 검증을 수행하고, 타깃별 데이터 실험을 통해 다양성과 효용성을 모두 확보했습니다.
2.3 모델 아키텍처
Kimi K2는 1.04조 개의 전체 파라미터와 326억 개의 활성화 파라미터를 가진 Mixture-of-Experts(MoE) 트랜스포머 모델입니다. 아키텍처는 DeepSeek-V3와 유사한 설계를 따르며, 어텐션 메커니즘으로 Multi-head Latent Attention(MLA)를 사용합니다. 모델의 은닉 차원(hidden dimension)은 7168이고, 각 MoE 전문가(expert)의 은닉 차원은 2048입니다.
 우리의 스케일링 법칙 분석에 따르면, 동일 활성 파라미터(즉, 고정 FLOPs) 하에서 전문가 총수를 늘려 희소성(sparsity)을 증가시키면 훈련 손실과 검증 손실이 모두 지속적으로 감소하여 성능이 향상되었습니다(Figure 5). 구체적으로, 검증 손실 1.5를 달성할 때, 희소성 48은 희소성 8, 16, 32에 비해 각각 1.69×, 1.39×, 1.15×의 FLOPs 절감을 가져왔습니다. 물론 희소성을 높이면 인프라 복잡도가 증가하므로, 성능과 비용의 균형을 고려하여 Kimi K2에서는 희소성 48(384개 전문가 중 8개 활성화)을 채택했습니다.
우리의 스케일링 법칙 분석에 따르면, 동일 활성 파라미터(즉, 고정 FLOPs) 하에서 전문가 총수를 늘려 희소성(sparsity)을 증가시키면 훈련 손실과 검증 손실이 모두 지속적으로 감소하여 성능이 향상되었습니다(Figure 5). 구체적으로, 검증 손실 1.5를 달성할 때, 희소성 48은 희소성 8, 16, 32에 비해 각각 1.69×, 1.39×, 1.15×의 FLOPs 절감을 가져왔습니다. 물론 희소성을 높이면 인프라 복잡도가 증가하므로, 성능과 비용의 균형을 고려하여 Kimi K2에서는 희소성 48(384개 전문가 중 8개 활성화)을 채택했습니다.
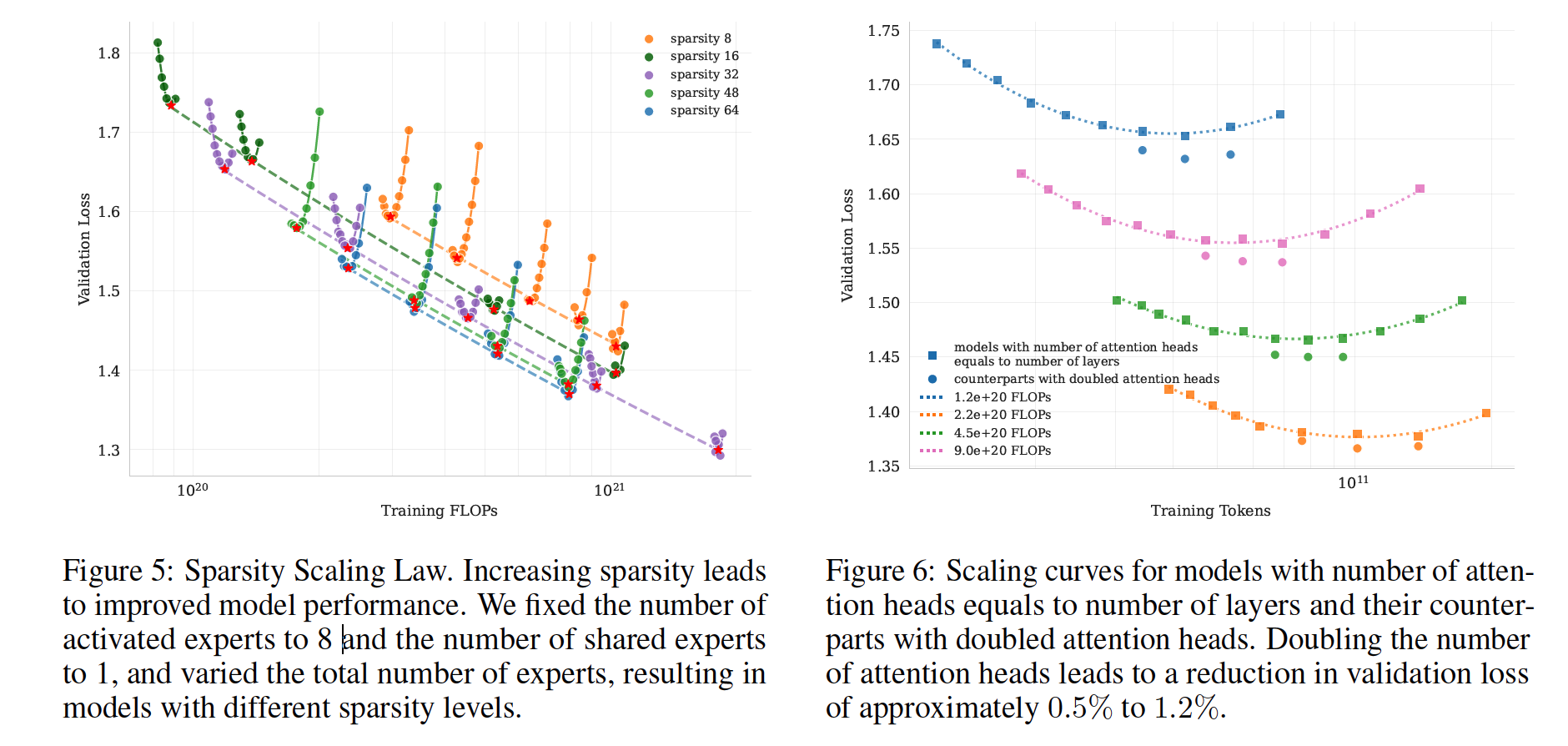 DeepSeek-V3는 메모리 대역폭 효율과 계산 효율성을 높이기 위해 레이어 수의 약 두 배인 128개의 어텐션 헤드를 사용했으나, 컨텍스트 길이가 길어질수록 추론 시 FLOPs 오버헤드가 크게 증가합니다. 예를 들어, 시퀀스 길이 128k에서 어텐션 헤드를 64→128로 늘리면 동일 전문가 수(384) 기준으로 추론 FLOPs가 83% 증가합니다. 이에 대한 영향을 평가하기 위해 레이어 수와 동일한 헤드 구성과 두 배 헤드 구성을 다양한 FLOPs 예산 하에서 비교 실험한 결과(Figure 6), 어텐션 헤드를 두 배로 늘려도 검증 손실이 0.5–1.2% 정도만 개선됨을 확인했습니다. 희소성 48이 이미 강력한 성능을 제공하므로, 헤드 수를 늘리는 마진 개선은 추론 비용 증가를 정당화하지 못한다고 판단했습니다.
DeepSeek-V3는 메모리 대역폭 효율과 계산 효율성을 높이기 위해 레이어 수의 약 두 배인 128개의 어텐션 헤드를 사용했으나, 컨텍스트 길이가 길어질수록 추론 시 FLOPs 오버헤드가 크게 증가합니다. 예를 들어, 시퀀스 길이 128k에서 어텐션 헤드를 64→128로 늘리면 동일 전문가 수(384) 기준으로 추론 FLOPs가 83% 증가합니다. 이에 대한 영향을 평가하기 위해 레이어 수와 동일한 헤드 구성과 두 배 헤드 구성을 다양한 FLOPs 예산 하에서 비교 실험한 결과(Figure 6), 어텐션 헤드를 두 배로 늘려도 검증 손실이 0.5–1.2% 정도만 개선됨을 확인했습니다. 희소성 48이 이미 강력한 성능을 제공하므로, 헤드 수를 늘리는 마진 개선은 추론 비용 증가를 정당화하지 못한다고 판단했습니다.
2.4 학습 인프라
2.4.1 컴퓨트 클러스터
Kimi K2는 NVIDIA H800 GPU로 구성된 클러스터에서 학습되었습니다. 각 H800 노드에는 2 TB의 RAM과 NVLink 및 NVSwitch로 연결된 8개의 GPU가 탑재되어 있습니다. 노드 간 통신은 8×400 Gbps RoCE 인터커넥트를 통해 이루어집니다.
2.4.2 모델 확장을 위한 병렬화 전략
대규모 언어 모델 학습은 종종 가용 자원이 동적으로 변하는 환경에서 진행됩니다. 특정 자원 규모에만 최적화된 단일 병렬화 전략 대신, Kimi K2는 32의 배수인 임의의 노드 개수에서 학습이 가능하도록 유연한 병렬화 방식을 채택합니다. 이 전략은 다음의 세 가지 병렬화를 조합합니다.
16-way 파이프라인 병렬화(Pipeline Parallelism, PP) with virtual stages
16-way 전문가 병렬화(Expert Parallelism, EP)
ZeRO-1 데이터 병렬화(Data Parallelism, DP)
이 설정 하에서, 모델 파라미터를 BF16으로, 그래디언트 누적 버퍼를 FP32로 저장하면 약 6 TB의 GPU 메모리가 필요하며, 이는 모델 병렬 그룹 256 GPU에 분산됩니다. 옵티마이저 상태(모멘텀, RMS 추정치 등)는 학습 노드 수에 따라 다음과 같이 배치됩니다.
노드 수가 많을 때: 옵티마이저 상태를 분산 저장하여 디바이스당 메모리 부담을 최소화
노드 수가 적을 때(예: 32 노드): 일부 옵티마이저 상태를 CPU로 오프로딩
이 디자인은 소규모와 대규모 실험 모두에서 동일한 병렬화 설정을 재사용할 수 있게 해 주며, 각 GPU에는 약 30 GB의 여유 메모리가 남아 activation을 저장할 수 있습니다(2.4.3 참조). 이렇게 일관된 구성은 시스템을 단순화하고 연구 반복 속도를 크게 향상시킵니다.
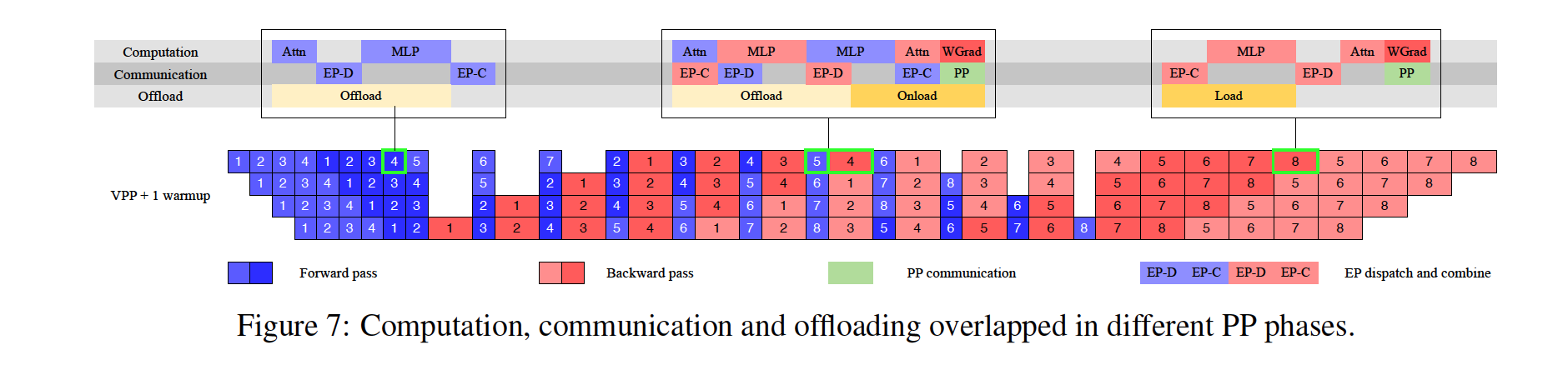 EP 통신 중첩과 1F1B 스케줄
EP 통신 중첩과 1F1B 스케줄
인터리브된 1F1B(Forward 1, Backward 1) 스케줄을 활용해, 여러 워밍업 마이크로배치를 두어 EP all-to-all 통신을 계산과 중첩(overlap)합니다. DualPipe처럼 메모리를 두 배로 쓰는 대신, PP 단계 수를 과도하게 늘리지 않고 EP 그룹 크기를 작게(16) 유지함으로써 통신 시간을 최소화했습니다.
2.4.3 Activation 메모리 절감
매 디바이스에 파라미터, 그래디언트 버퍼, 옵티마이저 상태를 저장한 후 남는 메모리만으로는 MoE activation을 모두 담기 어렵습니다. 특히 1F1B 워밍업 단계 중 상위 파이프라인 스테이지에서 activation이 급증하므로, 다음 기법을 통해 activation 메모리를 줄였습니다.
1.선택적 재계산(Selective Recomputation)
LayerNorm, SwiGLU, MLA up-projections 같은 연산량은 작지만 activation 크기가 큰 스테이지를 재계산합니다.
MoE down-projections도 재계산해 메모리를 아낍니다.
2.FP8 저장(Insensitive Activation Compression)
MoE up-projections와 SwiGLU 입력을 FP8-E4M3(1×128 타일, FP32 스케일)로 압축 저장합니다.
계산은 FP32로 수행하며, 소규모 실험에서 품질 저하가 관찰되지 않았습니다.
3.Activation CPU 오프로딩
나머지 activation을 CPU RAM으로 오프로딩(오프로드/온로드)해 GPU 메모리 부담을 줄입니다.
카피 엔진이 오프로드·온로드를 계산 및 통신과 중첩 처리합니다.
1F1B 단계에서는 이전 마이크로배치의 forward activation을 오프로딩하는 동시에, 다음 마이크로배치의 backward activation을 미리 페치(prefetch)합니다.
워밍업 및 쿨다운 단계도 동일한 패턴으로 처리합니다. PCIe 트래픽으로 인한 EP 통신 경합이 다소 있을 수 있으나, 실험에서는 EP 통신이 완전히 중첩됨을 확인했습니다.
2.5 학습 레시피
사전 학습 동안, 우리는 컨텍스트 윈도우 크기를 4,096 토큰으로 설정하고 MuonClip 옵티마이저(알고리즘 1)와 WSD 학습률 스케줄을 사용하여 총 15.5조 토큰을 처리했습니다.
1.처음 10조 토큰은 500스텝 워밍업 후 고정 학습률 2e-4로 학습
2.이후 5.5조 토큰은 코사인 감쇠로 학습률을 2e-4에서 2e-5로 점진 감소
3.전체 학습 기간 동안 가중치 감쇠(weight decay)는 0.1 고정
4.전역 배치 크기는 67백만 토큰으로 유지
사전 학습 후반부에는 어닐링(annealing) 단계와 장문 컨텍스트 활성화 단계를 거쳤습니다.
어닐링 단계: 배치 크기 67M 유지, 학습률을 2e-5에서 7e-6까지 추가 감쇠
장문 활성화 단계:
1.4k 시퀀스 길이로 4,000억 토큰 추가 학습
2.32k 시퀀스 길이로 600억 토큰 추가 학습
3.컨텍스트 윈도우를 128k로 확장하기 위해 YaRN 기법 적용
이와 같은 학습 레시피를 통해, 손실 곡선이 전체 과정에서 안정적으로 하강하며 단 한 번의 스파이크도 발생하지 않았습니다.
3 사후 학습(Post-Training)
3.1 지도형 미세조정(Supervised Fine-Tuning)
사후 학습 단계에서는 Muon 옵티마이저를 계속 사용하며, K2의 미세조정(fine-tuning)에도 Muon을 활용할 것을 권장합니다. 이는 이전 연구 Moonlight에서 Muon으로 사전 학습된 체크포인트가 Muon 미세조정 시 최상의 성능을 보인다는 결론을 따릅니다.
다양한 도메인을 아우르는 대규모 인스트럭션 튜닝(instruction-tuning) 데이터셋을 구축할 때는 다음 두 가지 원칙을 따릅니다.
1.프롬프트 다양성 극대화: 가능한 한 다양한 질문·지시 형태를 포함하여, 모델이 폭넓은 패턴에 노출되도록 합니다.
2.응답 품질 보장: 생성된 답변의 정확성·일관성·유용성이 높은지 확인합니다.
이를 위해 각 태스크 도메인별로 별도 설계된 데이터 생성 파이프라인을 개발했습니다. 이 파이프라인은
인간 주석(annotation),
프롬프트 엔지니어링(prompt engineering),
자동·수동 검증(verification)
단계를 결합하여, 후보 응답을 생성하고 품질을 평가·필터링합니다.
특히 에이전틱(agentic) 데이터(툴 사용·API 호출 등) 학습을 위해서는, 모델이 다단계 상호작용을 통해 도구 사용 능력을 익힐 수 있도록 데이터 합성 파이프라인을 구축했습니다.
3.1.1 대규모 에이전틱 데이터 합성(Agentic Data Synthesis)
현대 LLM 에이전트의 핵심 능력은 “미지의 도구를 자율적으로 사용하고”, “외부 환경과 상호작용하며”, “추론·실행·오류 보정을 반복하면서 행동을 정교화”할 수 있는 것입니다. 이러한 에이전틱 도구 사용(agentic tool use) 역량은 복잡한 다단계 태스크를 해결하는 데 필수적입니다.
그러나 대규모로 이러한 데이터를 수집하는 것은 비용·프라이버시·접근성 등의 제약으로 어려움이 많습니다. 최근 AgentInstruct, Self-Instruct, StableToolBench, ZeroSearch 등 합성 데이터 생성 연구가 대규모 데이터를 제공할 수 있음을 보여 주었습니다. 이를 바탕으로, ACEBench의 프레임워크를 참조해 다음과 같은 대규모 에이전틱 데이터 합성 파이프라인을 구축했습니다 (그림 8 참조).
1.툴 스펙 생성(Tool spec generation)
GitHub 등에서 수집한 3,000여 개 실제 MCP 도구 스펙과, LLM으로 합성한 20,000여 개 가상 도구 스펙을 통합합니다.
2.에이전트·태스크 생성(Agent and task generation)
각 도구 집합(tool-set)에 대해 가상의 에이전트(agent)와 수행할 작업(task) 시나리오를 설계합니다.
3.상호작용 궤적 생성(Trajectory generation)
에이전트가 연속적으로 도구를 호출하며 문제를 해결하는 multi-turn 상호작용 기록(trajectory) 을 시뮬레이션합니다.
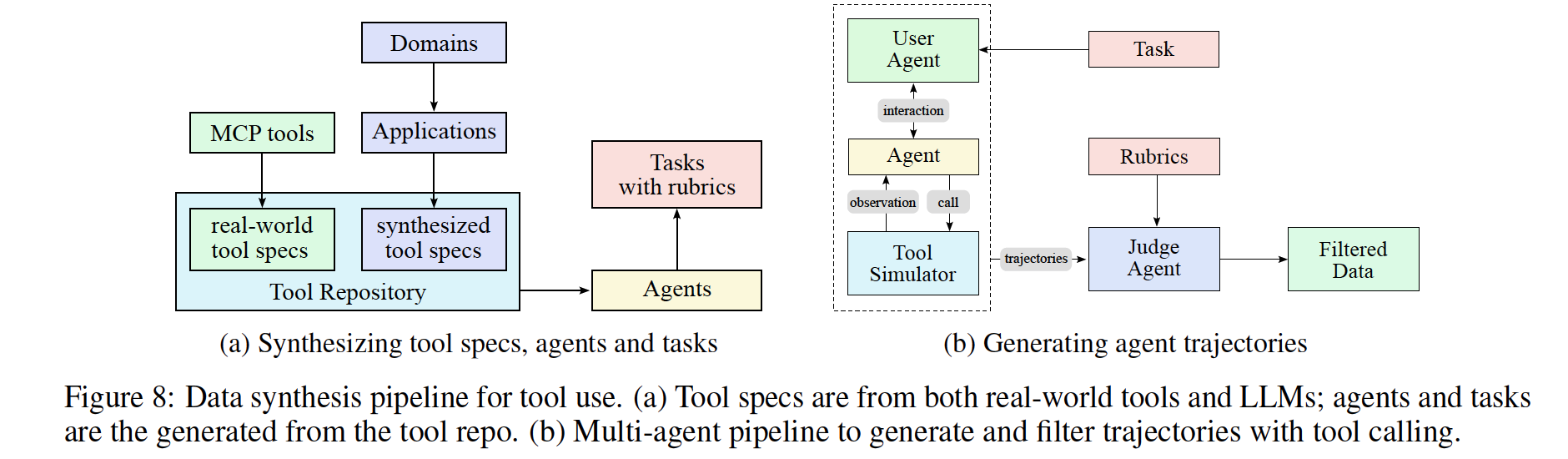
 도메인 진화 및 도구 생성
도메인 진화 및 도구 생성
도구 저장소를 포괄적으로 구축하기 위해 두 가지 상보적 접근 방식을 사용합니다.
첫째, GitHub 리포지토리에서 3,000개 이상의 실제 MCP(Model Context Protocol) 도구 스펙을 직접 수집하여, 기존의 고품질 도구 정의를 활용합니다.
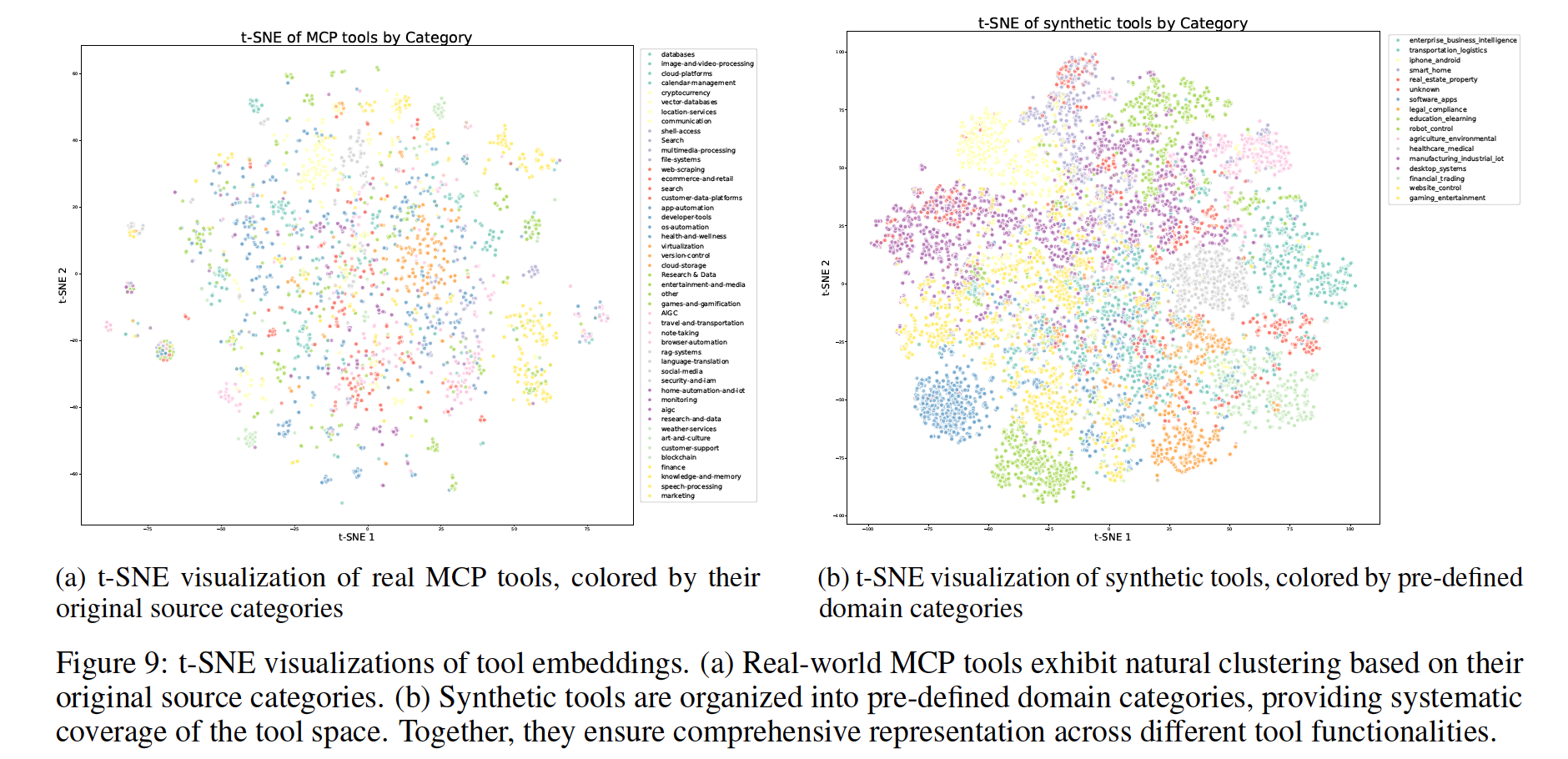
둘째, 계층적 도메인 생성 프로세스를 통해 합성 도구를 체계적으로 확장합니다. 주요 카테고리(예: 금융 거래, 소프트웨어 애플리케이션, 로봇 제어)로 시작하여, 각 카테고리 내에서 여러 세부 애플리케이션 도메인을 진화시킵니다. 각 도메인별로 명확한 인터페이스, 설명, 운영 의미론을 갖춘 전문화된 도구를 합성하며, 이 과정을 통해 20,000개 이상의 합성 도구를 생성합니다. 그림 9는 t-SNE 임베딩을 통해 MCP 도구와 합성 도구가 보완적으로 도구 공간을 커버함을 시각화합니다.
에이전트 다양화
도구 저장소에서 다양한 조합의 도구를 할당하고, 서로 다른 시스템 프롬프트를 합성하여 수천 개의 개별 에이전트를 생성합니다. 이를 통해 역량, 전문 분야, 행동 패턴이 다양한 에이전트 집단을 구성하여, 잠재적 사용 사례를 폭넓게 커버합니다.
루브릭 기반 태스크 생성
각 에이전트 구성에 대해 간단한 작업부터 복잡한 작업까지 범위를 갖는 태스크를 설계합니다. 각 태스크에는 성공 기준, 기대되는 도구 사용 패턴, 평가 체크포인트를 명시한 루브릭을 부여하여, 에이전트 성능을 일관되고 객관적으로 평가할 수 있도록 합니다.
다회차 궤적 생성
현실적인 도구 사용 시나리오를 시뮬레이션하기 위해 다음 요소들을 결합합니다.
사용자 시뮬레이션: 서로 다른 대화 스타일과 선호도를 지닌 LLM 기반 사용자 페르소나가 에이전트와 다회차 대화를 수행하여 자연스러운 상호작용 패턴을 만듭니다.
도구 실행 환경: 세계 모델과 유사한 기능을 갖춘 정교한 도구 시뮬레이터가 도구 호출을 실행하고 현실감 있는 피드백을 제공합니다. 각 호출 후 상태를 업데이트하여, 다단계 상호작용과 지속적 효과를 지원하며, 성공·부분 실패·예외 등 다양한 결과를 제어된 확률로 생성합니다.
품질 평가 및 필터링
LLM 기반의 판정자가 각 궤적을 루브릭에 따라 평가하여, 성공 기준을 충족하는 고품질 궤적만을 학습 데이터로 선별합니다. 이렇게 함으로써, 자연스러운 과제 수행 전략을 유지하면서도 데이터의 질을 보증합니다.
실제 실행 환경을 결합한 하이브리드 접근
시뮬레이션은 확장성에 유리하지만 실제성과 한계가 있으므로, 코딩 및 소프트웨어 엔지니어링 과제와 같이 현실성이 중요한 시나리오에는 실제 코드 샌드박스를 병행 사용합니다. 실제 샌드박스는 실제 코드를 실행하고 진짜 개발 환경과 상호작용하며, 테스트 스위트 통과율과 같은 객관적 지표로 피드백을 제공합니다. 이로써 시뮬레이션의 다양성과 실제 실행 환경의 진정성을 결합하여, 실용적인 에이전트 역량을 대폭 강화합니다.
이와 같은 확장 가능한 시뮬레이션과 타깃이 명확한 실제 실행의 하이브리드 파이프라인을 활용하여, 다양하면서도 높은 품질의 도구 사용 시연 데이터를 생성합니다. 자동화된 대규모 거절 샘플링을 통해 데이터 품질을 보증하며, 이 합성 데이터를 지도 학습에 활용했을 때 실제 애플리케이션 전반에 걸쳐 도구 사용 역량이 크게 향상됨을 확인했습니다.
3.2 강화학습(Reinforcement Learning)
강화학습(RL)은 SFT보다 토큰 효율(token efficiency)과 일반화(generalization) 능력이 더 뛰어나다고 여겨집니다. Kimi K1.5의 성과를 바탕으로, K2에서는 RL의 태스크 다양성과 학습 FLOPs를 모두 확장합니다. 이를 지원하기 위해, 다양한 시나리오에서 RL을 적용할 수 있는 Gym 유사 확장형 프레임워크를 개발했습니다. 이 프레임워크에는 검증 가능한 보상(verifiable rewards)을 제공하는 수많은 과제가 포함되어 있으며, 창의적 글쓰기나 개방형 질문 응답처럼 주관적 선호(preferences)가 중요한 경우에는 Self-Critique 보상을 도입하여 모델이 자신의 출력을 쌍별 비교(pairwise comparison) 방식으로 평가하도록 합니다. 이로써 다양한 도메인의 과제에 RL 패러다임이 골고루 적용되도록 했습니다.
3.2.1 검증 가능한 보상 Gym (Verifiable Rewards Gym)
1.수학, STEM, 논리 과제(Math, STEM and Logical Tasks)
다양성 유지(Diverse Coverage): 수학·STEM 과제에서는 전문가 주석, 내부 QA 추출 파이프라인, 공개 데이터셋을 결합해 고품질 QA 쌍을 수집하고, 태그 시스템으로 부족 분야를 보강합니다.
적절한 난이도(Moderate Difficulty): 지나치게 쉽거나 어려운 문제는 학습 신호가 약해지므로, SFT 모델의 pass@k 정확도를 기준으로 중간 난이도 문제만 선별합니다.
2.복합 지시 이행(Complex Instruction Following)
하이브리드 검증(Hybrid Rule Verification):
1)코드 인터프리터(code interpreter)를 이용한 결정적 평가(deterministic evaluation)
2)LLM 판정자(LLM-as-judge)를 활용한 자동 평가
3)허위 이행(fake compliance) 탐지를 위한 해크체크(hack-check) 계층
3.다중 출처 지시 생성(Multi-Source Instruction Generation):
1)전문가 제작 조건부 프롬프트
2)AutoIF 영감을 받은 에이전틱 지시 증강(agentic instruction augmentation)
3)특정 실패 모드를 겨냥한 세부 프롬프트 생성 전용 파인튜닝 모델
4.충실성(Faithfulness)
FACTS Grounding 프레임워크를 참고해, 문장 단위의 충실성 판정자(s faithfulness judge)를 학습하여 증거 없이 제시된 진술을 검출하고 보상 모델로 활용합니다.
5.코딩 및 소프트웨어 공학(Coding & Software Engineering)
대회 수준 문제: HumanEval, MBPP1 등 공개 데이터와 합성 소스 결합
테스트 일관성 확보: 사전학습 데이터에서 수집한 고품질 유닛 테스트(unit tests) 활용
소프트웨어 개발 환경: GitHub PR·이슈 대규모 수집, 쿠버네티스 기반 샌드박스(10,000+ 동시 인스턴스) 구축
5.안전성(Safety)
위험 범주 시드 프롬프트: 폭력·사기·차별 등 위험 카테고리를 포괄
자동화된 공격 진화:
1)공격 생성(Attack Model)
2)목표 모델 반응(Target Model)
3)판정자(Judge Model)
플러그인별 루브릭으로 성공/실패 평가
3.2.2 자기비판 루브릭 보상(Self-Critique Rubric Reward)
정량적 보상만으로 평가하기 어려운 주관적 과제(창의성, 유용성, 사실성, 안전성 등) 에 대응하기 위해, 모델이 스스로 평가하도록 하는 Self-Critique Rubric Reward를 도입했습니다.
1.Self-Critiqued Policy Optimization
K2 actor가 다양한 일반 프롬프트에 응답 생성
K2 critic가 쌍별 비교(pairwise evaluation)로 응답 순위 산정
핵심 루브릭(Core Rubrics): 명확성·대화 유창성·객관성
처방적 루브릭(Prescriptive Rubrics): 과도한 자기칭찬 금지, 불필요한 전언·과도한 이모티콘 등 배제
2.폐쇄형 루프(Close-Loop) 비평자 개선(Critic Refinement)
RLVR 과제 롤아웃 데이터를 이용해 critic 재학습
검증 가능한 과제에서 얻은 객관적 보상을 바탕으로 주관적 평가 지표를 보강
정책(policy)과 비평자(critic)의 공동 진화를 통해 평가 기준 상시 보정
이를 통해 Self-Critique는 외부 보상으로는 다루기 어려운 질적 요소를 보완하여, 모델의 행동(policy)을 종합적으로 향상시킵니다.